Anthropic 的 Harness 设计:build to delete
- 原文链接
- https://mp.weixin.qq.com/s/oRgwsF5TRJAZ-knedzGbuA
- 来源公众号
- AGI Hunt
- 作者
- J0hn
- 发布时间
- 2026-03-25
Anthropic 工程博客今天发了一篇关于 Harness 设计的文章,讲他们怎么让 Claude 完成长时间运行的全栈应用开发任务。造了一套相当复杂的编排系统,然后又亲手把它拆薄了。

关于什么是 Harness,可以先看我前面的文章:模型不是关键,Harness 才是

文中我专门提到了一个对立:Claude Code 团队的 Boris Cherny 和 Cat Wu 在 Latent Space 受访时明确表示,「所有的秘密武器都在模型本身,我们追求的是最薄的那层包装。」
这话当时被归入了「Big Model」阵营的代表性发言。
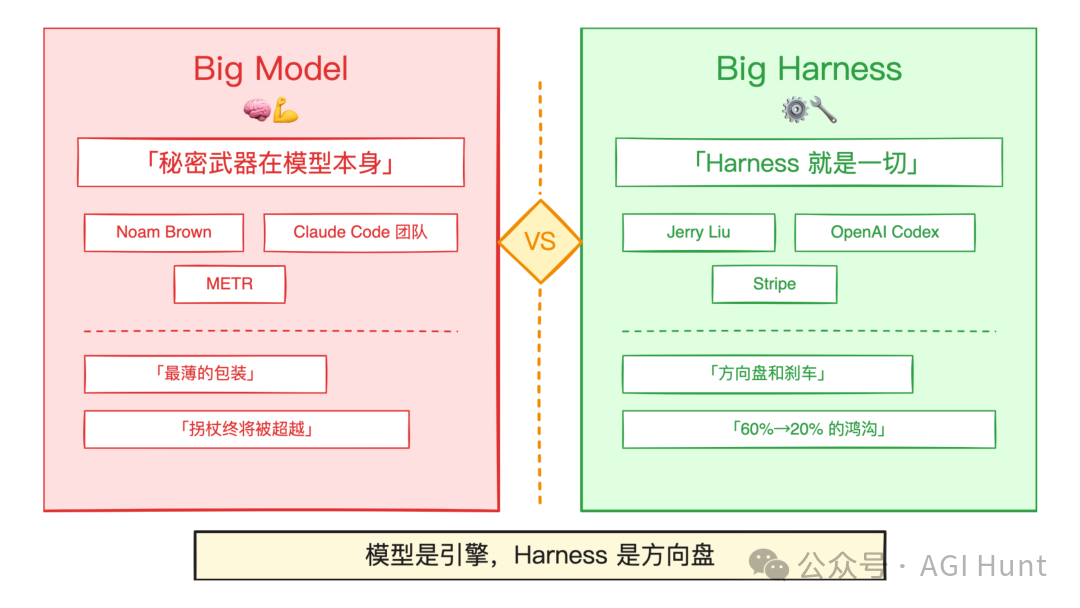
Big Model vs Big Harness 路线之争
结果五天之后,Anthropic 自己的工程博客就发了一篇详详细细的 Harness 设计方案,GAN 式对抗架构、三 Agent 分工、sprint 合约、Playwright 自动化测试……
这层「包装」,说实话,一点都不薄。
所以到底是「Big Model」还是「Big Harness」呢?
读完这篇博客你会发现,答案可能是:都是,但要看时机。
两个老毛病
文章的作者是 Anthropic Labs 的 Prithvi Rajasekaran,开篇就点出了单 Agent 模式的两个致命问题。
上下文退化。 任务一长,context window 被塞满,模型表现明显下滑。有些模型甚至会出现一种「上下文焦虑」,觉得快到 context 上限了,就草草收工。
团队发现,对 Sonnet 4.5 来说,与其压缩上下文,不如直接清空重来,把之前的成果做结构化交接。这个经验倒是和 Cursor 团队的发现一致,他们在 Self-Driving Codebases 研究中也走过同样的弯路。
自我评估偏差。 让 Agent 自己评价自己写的代码,结果往往是一通自夸。尤其是前端设计这种主观性很强的任务,毕竟没有一个二进制的「对错」可以判定。
这两个问题,其实在之前的 Harness Engineering 讨论中都被提到过。OpenAI 的解法是架构约束加 linter 硬编码;Stripe 的解法是 CI 限速加 Blueprint 编排。
而 Anthropic 则选了一条不太一样的路。
GAN 式对抗
他们的灵感来自 GAN(生成对抗网络)。
把「生成」和「评估」拆给两个不同的 Agent,让评估者用具体的打分标准把主观判断变成可量化的指标。前端设计任务的四项评分标准:
- 设计质量:视觉上是否连贯,有没有自己的辨识度
- 原创性:有没有独立的设计决策,还是千篇一律的 AI 味
- 工艺:排版、间距、配色和谐度
- 功能性:可用性和任务完成度
评估 Agent 用 Playwright 去操作实际页面,截图、点击、测试,然后打分。每一轮生成通常要经过 5 到 15 次迭代,整个过程可能持续长达 4 小时。
跟 OpenAI 和 Stripe 的路线完全不同:它们用的是「硬约束」(linter 挂掉就不给过),Anthropic 走的是「软对抗」,让两个 Agent 互相博弈。
评估 Agent 做的并非规则执行,更像是在做判断。这在前端设计这种没有标准答案的场景下,可能确实比硬编码的 linter 更合适。
三个角色
全栈编程任务则上了更完整的编排。三个 Agent,各管一摊:
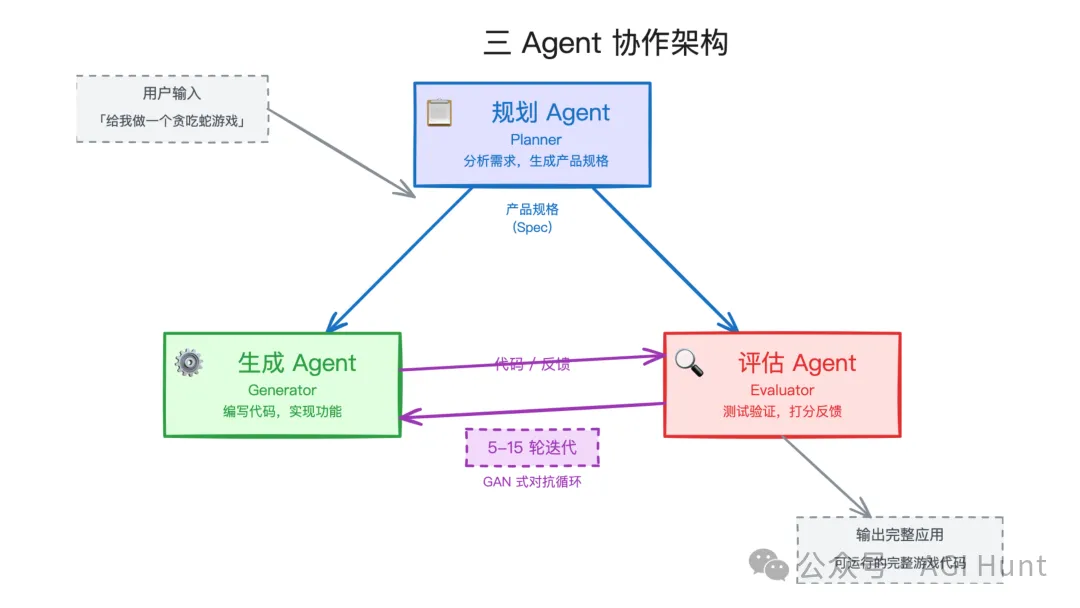
三 Agent 协作架构:规划、生成、评估形成对抗式迭代循环
规划 Agent。 把用户一两句话的需求扩展成完整的产品规格。关键是要有野心,范围定得大,但不过度指定实现细节。它还会主动在规格中加入 AI 功能,这一点倒是挺「Anthropic」的。
生成 Agent。 按 sprint 计划逐步实现功能,技术栈是 React + Vite + FastAPI + SQLite/PostgreSQL,全程 git 版本管理。提交 QA 之前会先做一轮自检。
评估 Agent。 用 Playwright 像真实用户一样操作应用,点功能、测 API。在实现开始前,它会和生成 Agent 协商一个「sprint 合约」,定义验收标准。
sprint 合约这个机制,跟其他公司的做法形成了鲜明对比。Stripe 的 Minions 用的是 Blueprint 编排,确定性节点和 Agentic 节点交替执行:
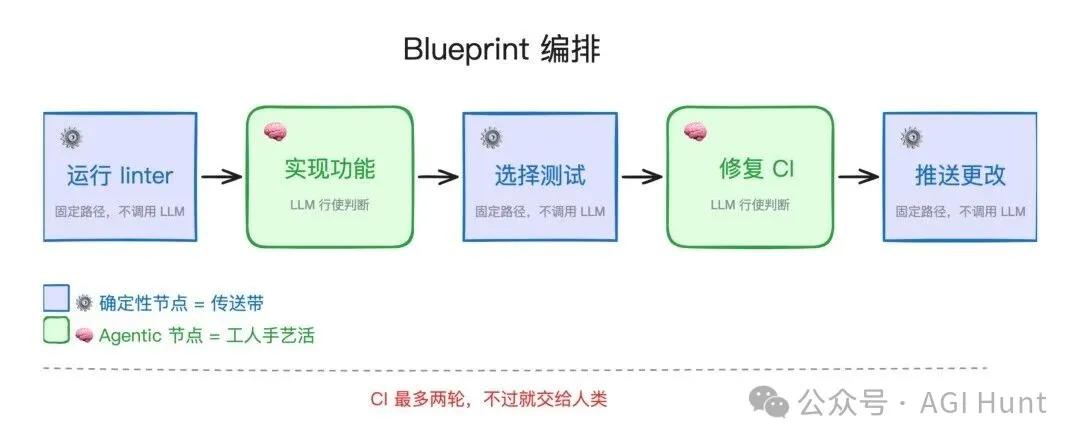
Blueprint 编排:确定性与 Agentic 节点交替
Cursor 最终走的是递归 Planner-Worker 模型。
而 Anthropic 选了「合约」这个隐喻,让 Agent 之间先谈好再干活。
三种公司,三种编排哲学,但核心逻辑其实一样:别让 Agent 自由发挥,给它框架。
效果对比
拿复古游戏编辑器(Retro Game Maker)来做对比,用的是 Opus 4.5:
| 方式 | 耗时 | 成本 |
|---|---|---|
| 单 Agent | 20 分钟 | $9 |
| 多智能体编排 | 6 小时 | $200 |
单 Agent 的产出:
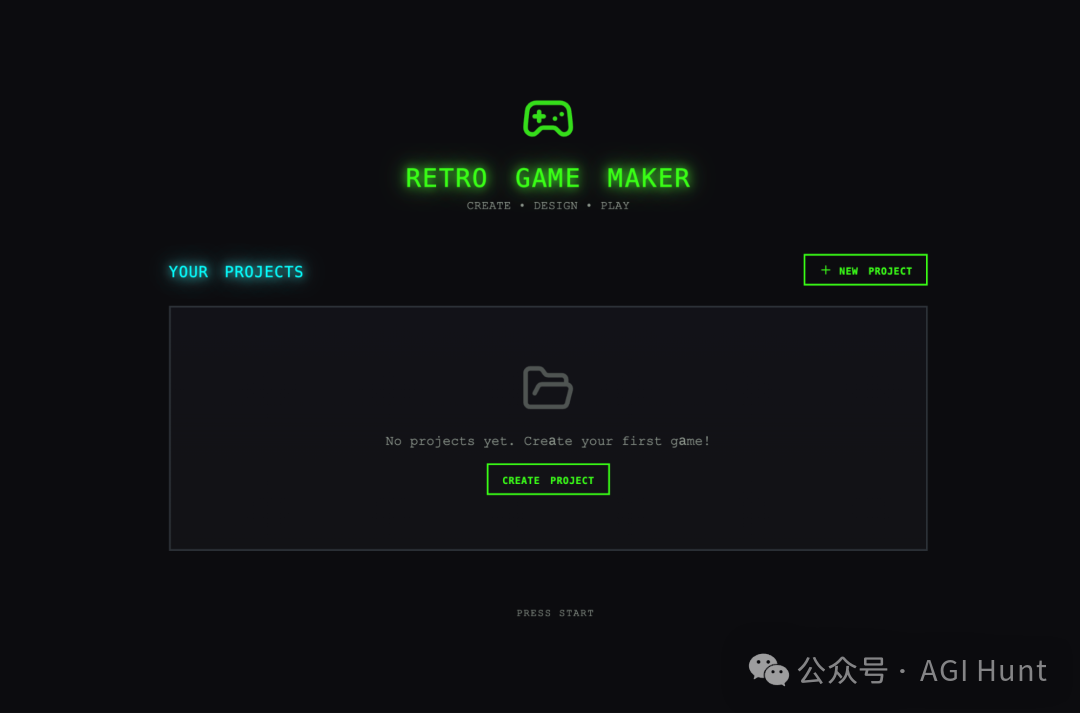
单 Agent 生成的游戏编辑器首页
能跑,但……游戏实体连线是断的,工作流死板,UI 不直观,屏幕空间大量浪费。

单 Agent 的精灵编辑器
那……试着玩一下呢?
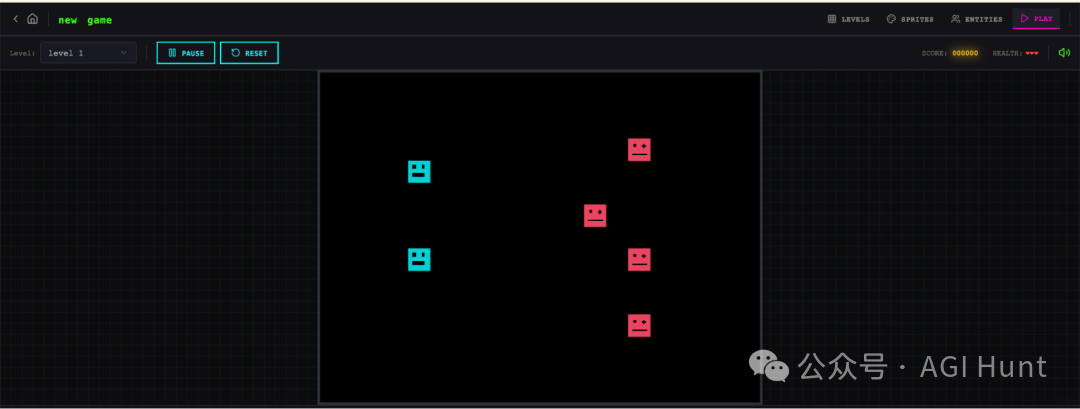
在单 Agent 生成的游戏中尝试玩关卡,失败了
基本不能正常游玩。
而多智能体编排的版本:
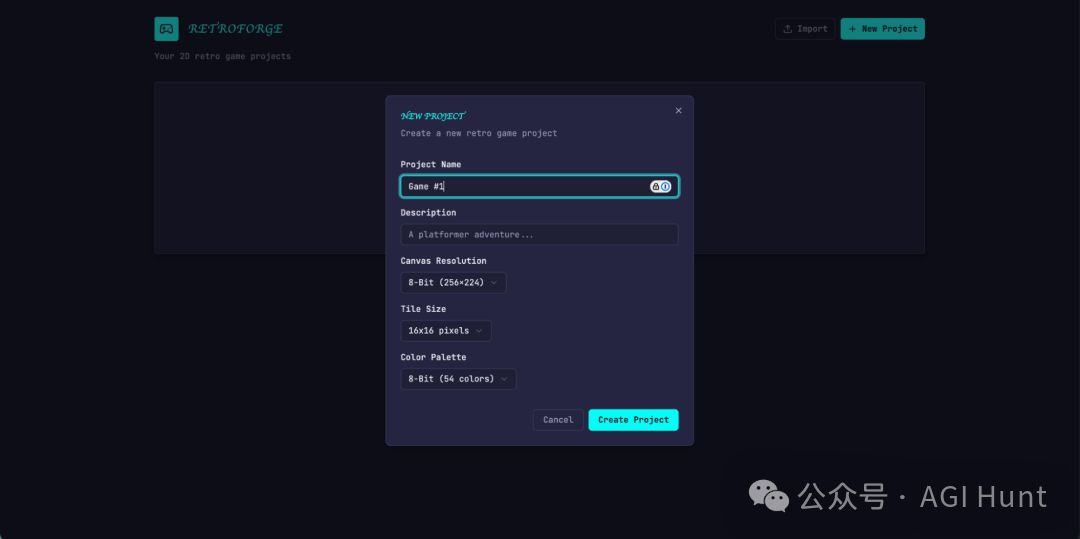
多智能体编排生成的 RetroForge 新建项目界面
打磨感和一致性上了一个台阶,工作流也变得直观了不少,还集成了 Claude AI 辅助生成精灵和关卡。
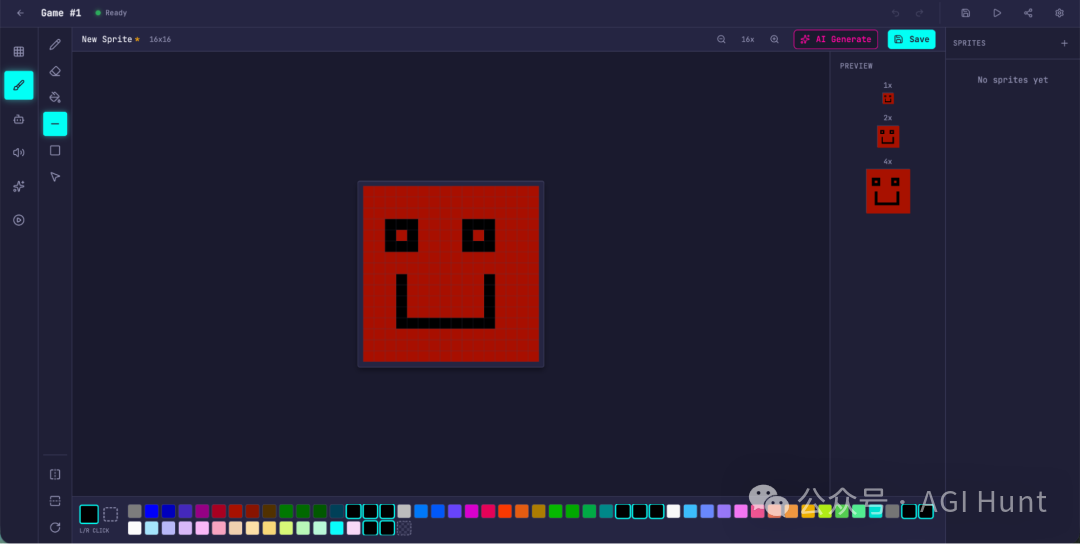
多智能体版本的精灵编辑器
游戏机制是能正常运转的:
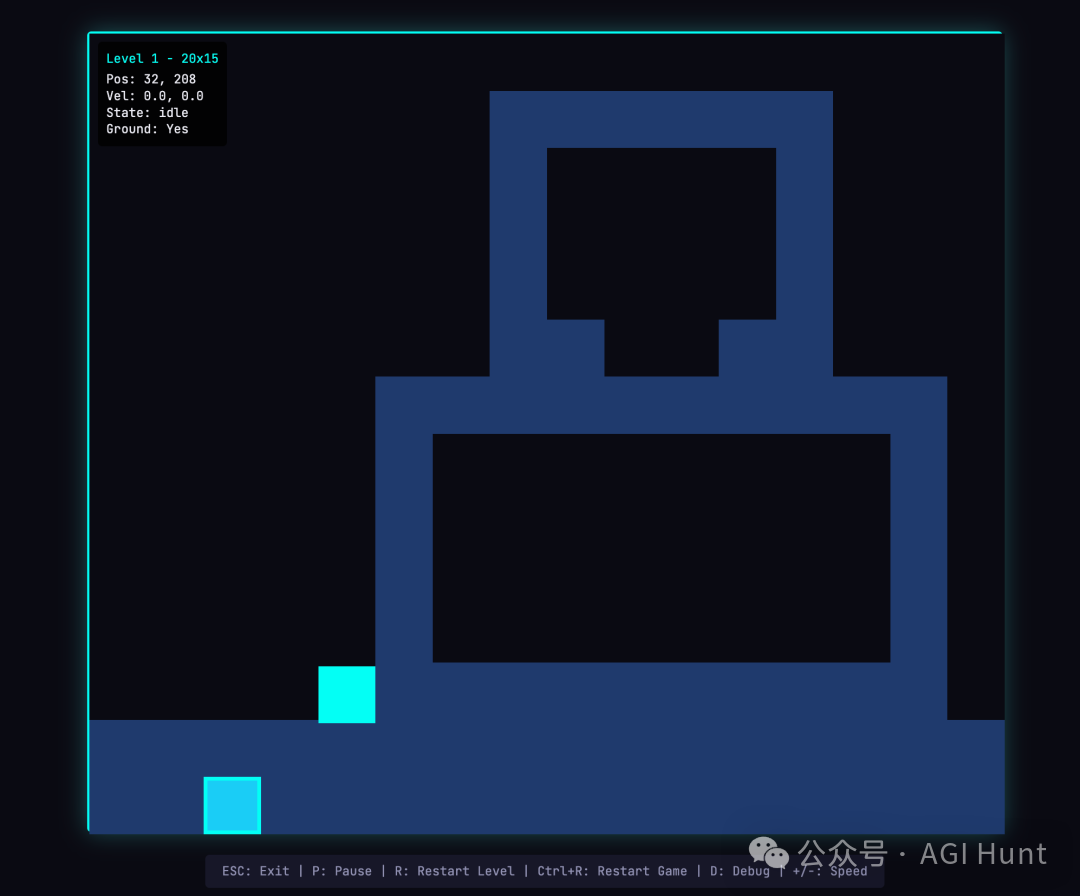
用多智能体版本生成的关卡可以正常游玩
9 美元 vs 200 美元,成本差了 20 多倍,但产出完全是两个量级的东西。
这个对比也呼应了 Nate B Jones 的发现:同一个模型,换一套 Harness,结果天壤之别。
调教评估者
让评估 Agent 真正发挥作用,其实比想象中要难一些。
开箱即用的 Claude 在做 QA 时有个通病:发现了问题,然后自己说「不过这也还行」,就放过了。或者只做表面测试,不深入探索边界情况。
这跟 OpenAI 团队的经验不谋而合。
他们也发现 Agent 在「自我评估」时过于宽容,所以才设计了 linter 和结构测试这样的硬约束。
Anthropic 的做法是花大量时间迭代评估 prompt,让评估 Agent 变得足够挑剔。来看几个评估 Agent 抓到的真实 bug:
矩形填充工具只在拖拽端点处放置了图块,并没有真的填充整个区域。
删除键的处理逻辑要求同时满足
selection和selectedEntityId,但正确逻辑应该是满足其中之一即可。
路由排列顺序导致 FastAPI 把 'reorder' 当作整数类型的 frame_id 去解析,返回了 422 错误。
这些都是人类 QA 工程师会抓到的实际 bug。
团队总结了一个关键发现:让外部评审变得挑剔,比让生成者学会自省,要容易得多。
这句话,放在整个 Harness Engineering 的语境下看,其实在说一件更深的事:与其指望模型自己变完美(Big Model 路线),不如在模型外面建一套纠错机制(Big Harness 路线)。
至少在当下,后者更可行。
做减法
然后……Opus 4.6 来了。
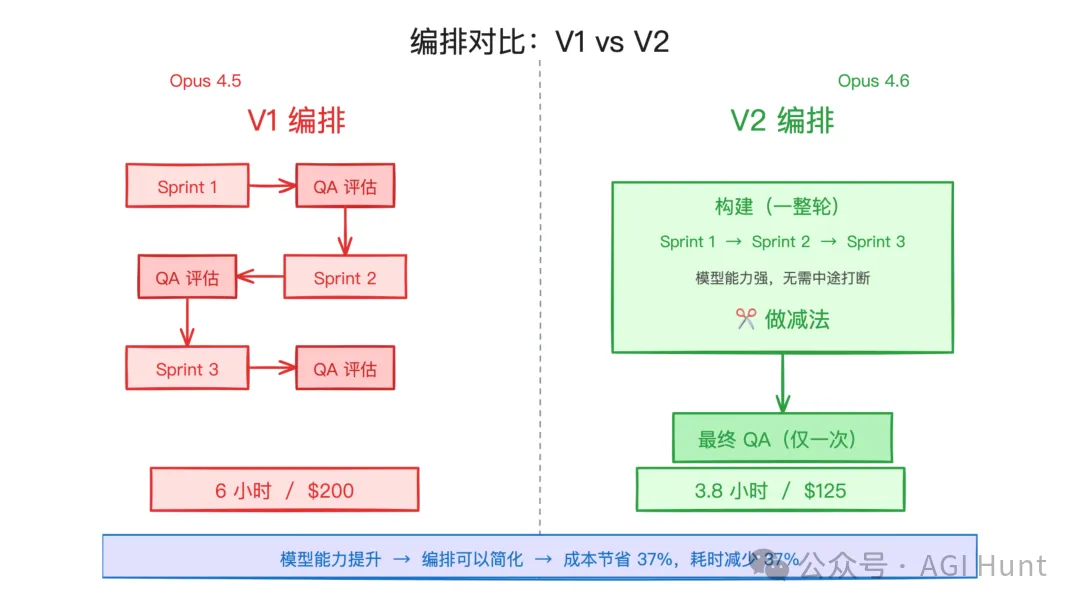
V1 vs V2 编排对比:模型能力提升后编排可以简化
这是这篇博客最精彩的部分。
Opus 4.6 在规划能力、长时间任务持续性、代码审查等方面都有了显著提升。于是团队重新审视了之前的假设。
去掉了 sprint 分解。 Opus 4.6 能在更长的会话中保持连贯,不再需要 sprint 这个脚手架了。
评估后移。 从每个 sprint 结束都评估,改成了整个构建完成后统一评估。
简化后的 V2 编排做了什么呢?
用户输入只有一句话:「在浏览器里用 Web Audio API 构建一个全功能的 DAW。」
| 环节 | 耗时 | 成本 |
|---|---|---|
| 规划 | 4.7 分钟 | $0.46 |
| 构建第 1 轮 | 2 小时 7 分钟 | $71.08 |
| QA 第 1 轮 | 8.8 分钟 | $3.24 |
| 构建第 2 轮 | 1 小时 2 分钟 | $36.89 |
| QA 第 2 轮 | 6.8 分钟 | $3.09 |
| 构建第 3 轮 | 10.9 分钟 | $5.88 |
| QA 第 3 轮 | 9.6 分钟 | $4.06 |
| 总计 | 3 小时 50 分钟 | $124.70 |
一句话变成了一个能在浏览器里跑的 DAW,有编排视图、混音器、播放控制。Agent 甚至能用这些工具自主作曲。
Anthropic 的 Harness 设计:build to delete
Anthropic 的 Harness 设计:build to delete
总共不到 4 小时,125 美元。
护栏进化论
这篇博客最后给出了五条总结,但我觉得真正重要的只有一条:
Harness complexity is load-bearing but not permanent. 编排的复杂度是有承重的,但不是永久的。
这句话,精准地回答了上篇文章里「Big Model vs Big Harness」的争论。
我在文章中提了一个概念叫「护栏悖论」:车速越快,护栏越重要。
模型越强,你越需要精心设计的约束系统。
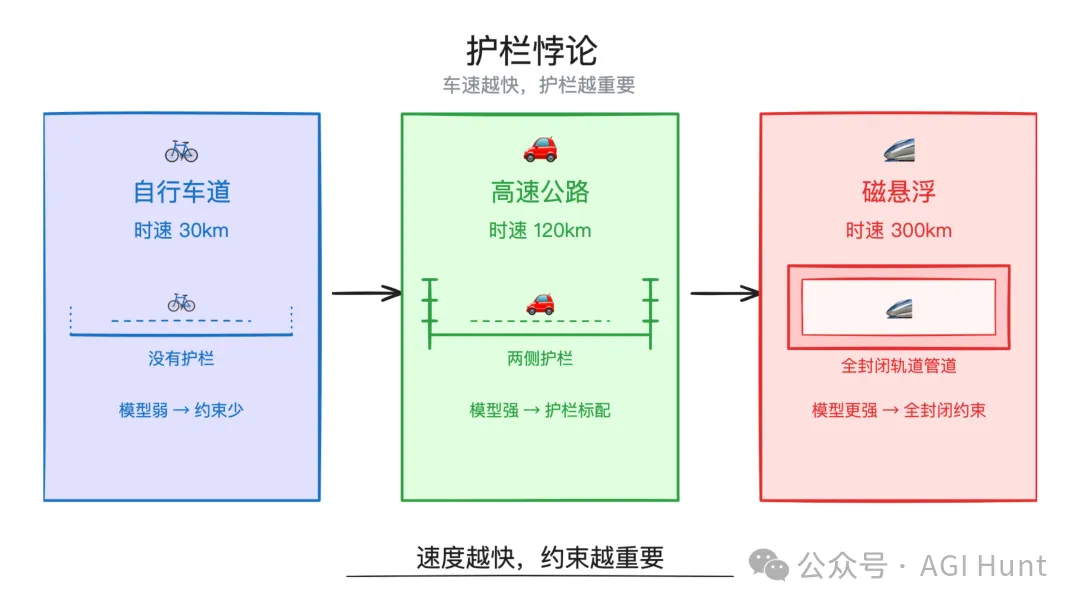
护栏悖论:车速越快护栏越重要
Anthropic 这篇博客给了这个悖论一个补充:护栏也会随着车的进化而改变形态。
V1 的 Harness 有 sprint 分解、有每轮评估、有复杂的合约机制。
Opus 4.6 出来之后,sprint 不要了,评估后移了,整体简化了。从 6 小时 $200 变成了 3.8 小时 $125。
这也恰好验证了 Philipp Schmid 的观察:
Manus 在 6 个月内重构了 5 次 Harness,LangChain 一年内重新架构了 3 次。Harness 并非一劳永逸的基础设施,它需要跟着模型能力一起演进。
所以 Boris Cherny 说的「追求最薄的包装」和团队实际做的「三 Agent 对抗编排」,其实并不矛盾。关键词是「追求」:目标是薄,但现实中厚度取决于模型当前的能力边界。
模型还不够强的地方,Harness 就得补上;模型变强了,对应的 Harness 就该被剥离。
Noam Brown 说「别花六个月搭建一个六个月后就被淘汰的东西」,Anthropic 的回答是:那就别搭一个六个月都拆不掉的东西。
V1 到 V2 的演进说明了他们的 Harness 确实是模块化、可拆卸的。sprint 分解该去就去,评估频率该调就调。
这可能才是 Harness Engineering 最重要的设计原则:Build to Delete。
造出来,是为了有一天能拆掉。
相关链接:
- Anthropic 原文:https://www.anthropic.com/engineering/harness-design-long-running-apps
- 推文:https://x.com/AnthropicAI/status/2036481033621623056