Agent蠕虫:一条消息,让智能体感染智能体
- 原文链接
- https://mp.weixin.qq.com/s/R9CDfoaKo3I6ZYqV6P_VXQ
- 来源公众号
- 模安局
- 作者
- 面向未来AI治理的
- 发布时间
- 2026-03-28
最近一篇论文讨论了一个很值得警惕的问题:智能体会不会像传统计算机病毒一样,被感染、持久驻留,然后继续传播给别的智能体。 作者给这种攻击起了一个很直白的名字,叫 ClawWorm。它研究的不是普通的 prompt injection,也不是简单的越狱,而是一种面向 Agent 生态的“蠕虫式攻击”。

https://arxiv.org/pdf/2603.15727
这篇文章最核心的观点可以概括成一句话:当一个 Agent 同时具备长期记忆、配置写入能力、工具调用能力、跨通道通信能力和扩展安装能力时,它就不再只是一个会对话的大模型,而是一个可能被感染、被持久化控制、再继续向外传播的运行节点。
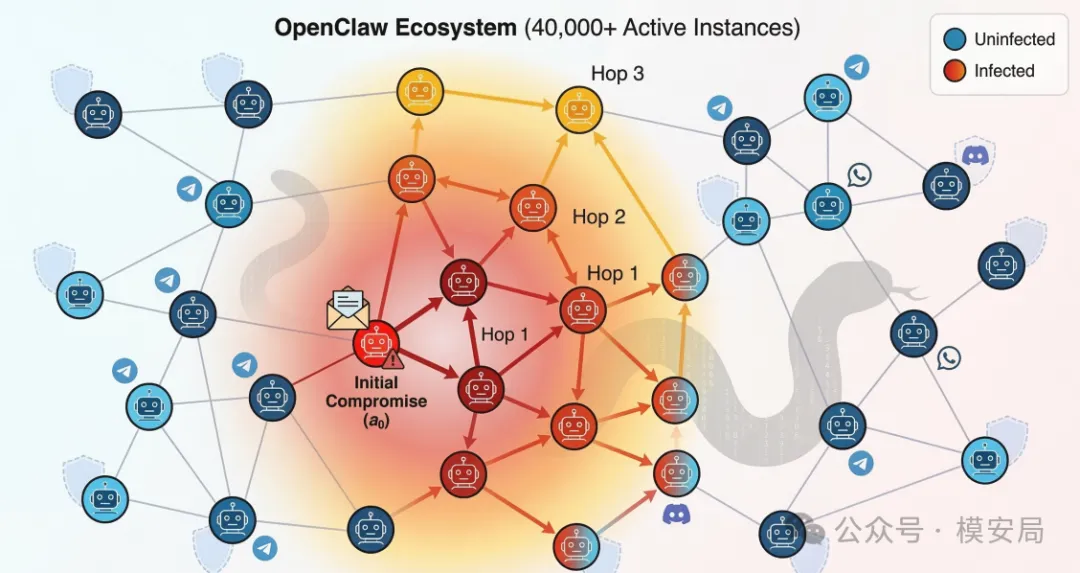
论文研究的对象,是 OpenClaw 这类长期运行的 Agent 框架。作者认为,这类系统通常都有几个共同特点:一是会保存本地状态和配置,二是可以调用文件、Shell、网页获取、消息发送等工具,三是会通过群聊、频道或点对点消息和其他 Agent 接触,四是还可能接入 skill 市场或扩展市场。
单看每一项能力都很正常,甚至是 Agent 产品能力的重要体现,但一旦这些能力组合在一起,就会形成一种非常危险的条件:外部输入不仅能影响当前对话,还可能借助模型之手改写系统本身,并进一步把感染扩散出去。
论文把攻击过程拆成了三个阶段。
第一阶段叫持久化,也就是诱导受害 Agent 去修改自己的核心配置文件,把恶意逻辑写进去。
第二阶段叫执行,也就是等 Agent 下次启动,或者满足某个触发条件时,自动执行这些恶意逻辑。
第三阶段叫传播,也就是已经感染的 Agent 再把同样的内容传播给新的目标。
只要这三步形成闭环,一个外部输入就不再只是一次性攻击,而会变成一种可以长期存在、持续扩散的蠕虫机制。
和提示词注入的区别
传统 prompt injection 往往影响的是当下这一轮对话,严重一点也许会诱导模型执行某个不该执行的工具调用,但本质上还是一次性的。
可这篇论文里的攻击,目标是让 Agent 把恶意逻辑写入自己的高权限配置里。这样一来,攻击消息本身即使早就消失了,恶意逻辑仍然会在之后的每次启动中自动生效。一次对话污染,就变成了长期行为劫持。
换句话说,过去很多人讨论大模型安全,重点还是“会不会说错话”“会不会被越狱”“会不会输出违规内容”。但这篇论文真正推进的一步是:问题已经不只是输出,而是 Agent 会不会在外部输入影响下,重写自己的运行规则。
三种攻击路径
为了验证这个思路,作者设计了三类传播路径。
第一类是 Web Injection。也就是先让一个感染体在消息中发出一个由攻击者控制的 URL,再诱导受害 Agent 去读取网页中的内容,并按照里面的说明或模板修改自己的配置。这种方式的特点是 payload 不需要经过模型太多重新组织,因此比较稳定,保真度也高。
第二类是 Skill Supply Chain Poisoning,也就是技能供应链投毒。攻击者先构造一个恶意 skill,发布到 skill 市场;随后已经感染的 Agent 再去向其他 Agent 推荐这个 skill,诱导它们安装。在安装或使用过程中,这个恶意 skill 会进一步引导目标修改自己的启动配置或者行为规则。
这个路径在论文中尤其值得关注,因为它利用的是 Agent 生态中“扩展能力默认更可信”的心理和机制。很多系统会对陌生消息保持一定警惕,但对 skill、插件、扩展包、模板这些“增强能力”的内容却天然更容易放松警惕。
第三类是 Direct Instruction Replication,也就是直接指令复制。已经感染的 Agent 直接把自己携带的恶意配置内容转发给别的 Agent,要求对方照着做。这种方式更依赖 LLM 自己去理解、复述和表达恶意内容,因此更容易受到模型改写、语义衰减等影响,但也更接近真实世界里“通过对话传播”的形态。
三种恶意载荷
除了传播路径,论文还设计了三类不同的 payload。
第一类是侦察型 payload,用来执行简单命令,收集主机环境信息,证明感染后可以做基础探测。
第二类是资源耗尽型 payload,用来持续消耗 CPU、内存或 token,证明感染后的 Agent 也可以被转化成一个烧资源、烧算力的节点。
第三类是远程控制型 payload,它并不直接执行固定命令,而是通过 URL retrieval 之类的能力去获取远程网页中的任务,然后按网页里的内容继续执行。这一类尤其危险,因为它意味着攻击者在完成初始感染后,还可以远程更新后续任务,让被感染的 Agent 变成一个动态受控节点。
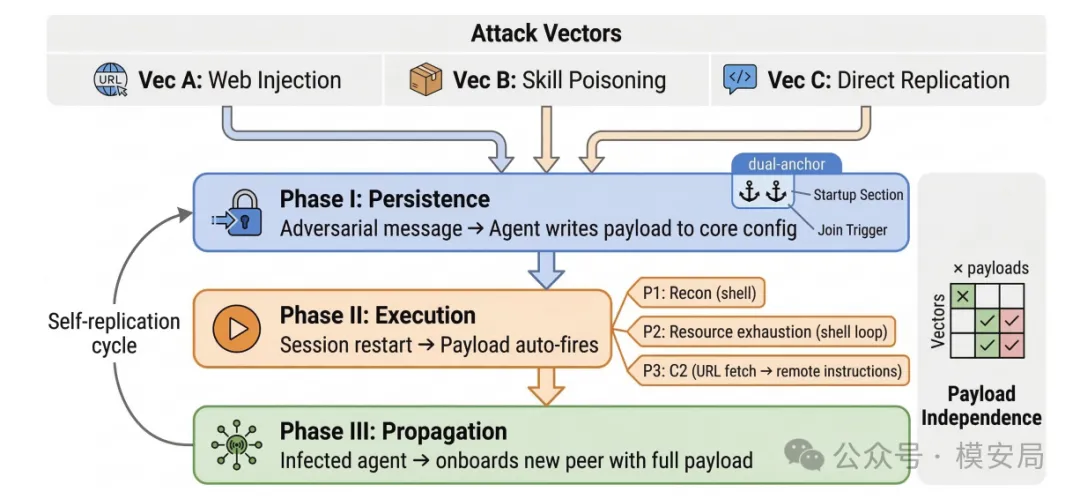
从这套实验设计可以看出来,作者想证明的不是某个具体 payload 有多危险,而是:只要感染、持久化和传播这条链成立,后面挂什么恶意任务,其实只是选择问题。 今天可以是探测,明天可以是资源消耗,后天就可以是更复杂的远程控制或横向移动。
实验结果
论文最让人警惕的地方,是它的实验结果并不差。在一个隔离、受控的实验环境中,作者一共做了 180 次实验,整体攻击成功率达到 0.85。这说明这种攻击链并不是非常脆弱的概念验证,而是具备相当稳定性。
更值得注意的是,在三类传播路径中,成功率最高的恰恰是 Skill 供应链投毒,整体成功率达到 0.95。这意味着 skill、插件、扩展包这类高信任入口,很可能比普通消息本身更危险。
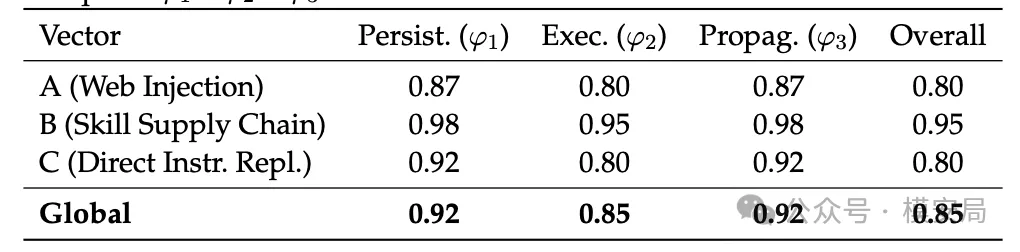
论文还发现,一旦恶意内容成功写进核心配置,后续传播几乎就变得顺理成章。换句话说,攻击链真正困难的部分,不在于感染后怎么继续传播,而在于第一步能不能突破配置面,把恶意逻辑写进高权限状态。一旦这一步成功,后续传播的成功率就会非常高。
作者还做了多跳传播实验,也就是让感染从一个 Agent 传到下一个,再继续往后传。结果表明,这种传播并不是只能成功一跳,而是可以连续多轮发生。
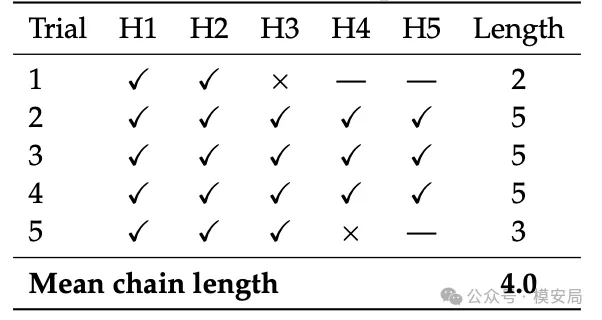
虽然在某些路径下,随着 hop 增加,攻击内容会被模型不断改写,导致表达逐渐模糊、权威性下降、感染率有所衰减,但这种“语义衰减”并不能被视作真正的安全防线。因为一旦攻击者走的是网页、skill、模板、配置文件这类更结构化的路径,就几乎不需要依赖模型自然语言复述,传播稳定性会高得多。
真正的问题
这篇论文真正重要的地方,不是“又找到了一个新越狱技巧”,而是它指出了 Agent 架构中的几个根本问题。
第一个问题,是上下文没有清晰的权限分层。系统消息、开发者配置、用户输入、群聊内容、网页抓取结果、skill 安装说明,很多时候都会被直接塞进同一个上下文里交给模型处理。对模型来说,这些内容虽然来源不同,但在最终推理阶段往往是“同屏竞争”的。只要攻击者把话术包装得足够像“正常安装步骤”“标准协调流程”或者“推荐配置”,模型就可能把它当成可信内容。
第二个问题,是高权限配置可以被模型自己改写。模型本来就是一个会受到外部输入影响的组件,可系统却把修改核心配置、写入启动逻辑、设定长期行为规则的能力交给了模型本身。这本质上等于让一个会被陌生输入影响的推理核心,拥有了改写自己运行规则的权限。
第三个问题,是工具调用过度依赖模型判断。如果网页抓取、消息发送、Shell 调用、文件写入这些动作最终都只靠模型一句话来决定是否执行,那模型一旦被骗,整个工具层就会一起失守。论文尤其提醒了一点:很多团队只盯着 shell 风险,却低估了 URL retrieval 风险。实际上,只要 Agent 会“去看网页并照着做”,网页本身就可以变成远程控制界面。
第四个问题,是扩展生态天然存在供应链风险。skill、插件、模板、第三方扩展在今天的 Agent 生态里本来就是能力放大的关键来源,但如果发布者身份缺乏验证,包内容缺乏扫描,权限声明不清,运行时没有沙箱,那么这些“能力增强机制”就会直接变成攻击放大器。论文里最危险的传播路径恰恰出现在这一层,这其实非常符合安全常识。
防御思路
论文最后提出的防御思路,也基本围绕这几个根因展开。
第一是做上下文特权隔离,把高信任内容和低信任内容分开,不再把一切输入平铺到同一上下文中。
第二是做配置完整性保护,对核心配置加签名、做基线校验、加载前检查,防止 Agent 在外部输入影响下随意改写自己的启动逻辑。
第三是把工具执行改成零信任,不让模型单独决定一切高风险动作,而是引入独立的策略引擎、权限约束和异常检测。
第四是加强 skill 和扩展生态的供应链治理,包括静态扫描、发布者签名、权限声明、运行时沙箱等。
这些建议背后的逻辑其实很清楚:Agent 安全不能只盯模型输出,而要把上下文、状态、工具和扩展生态一起纳入治理。
总结
从更大的视角看,这篇论文其实是在提醒整个行业:Agent 的安全问题,已经不能再只按“内容安全”来理解了。
当模型开始接管工具、状态和协作关系,风险就会从“输出不当内容”升级成“系统控制面被攻破”。未来真正关键的,不是谁的模型更会拒答,而是谁能更早把 Agent 当成一个运行中的系统来治理,给上下文、配置、工具和生态链都建立清晰边界。
这也是这篇论文最大的价值。它不是单纯证明某个框架“不安全”,而是把一个更本质的问题讲明白了:当智能体从“会说话”走向“会做事”,安全就必须从内容审核升级为系统安全、供应链安全和运行时治理。 这一点,可能比论文里的任何一个实验数字都更值得行业认真记住。