Harness Engineering:AI 时代真正稀缺的,不再是模型能力,而是“把智能管起来”的能力
- 原文链接
- https://mp.weixin.qq.com/s/9iP5YAgFm2E5wgmH2mxn1g
- 来源公众号
- 智汇资管科技导航
- 作者
- John Zhang
- 发布时间
- 2026-03-31
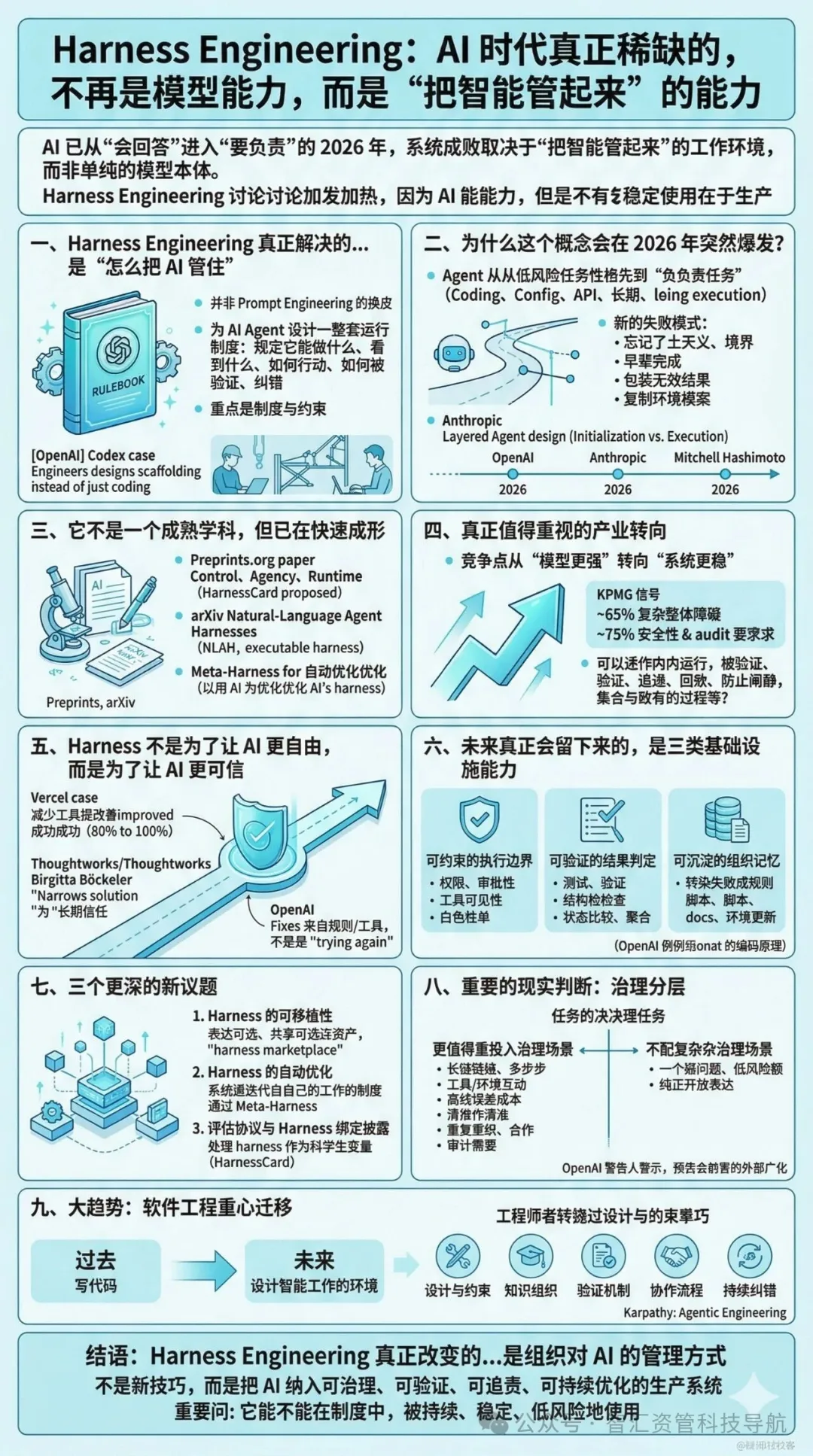
决定 AI 能否真正进入生产系统、承担连续工作、创造可复用价值的,已经不只是模型本身,而是模型被放进了一个什么样的工作环境。Harness Engineering 之所以在 2026 年突然升温,不是因为行业又多了一个新名词,而是因为大家同时撞上了同一个问题:AI 会做事了,但还不会被稳定地使用。
过去两年,AI 行业最热的讨论,几乎都围绕模型展开:参数规模、推理能力、上下文长度、工具调用、代码生成、Agent 框架。 但到了 2026 年,一个越来越清晰的现实正在浮出水面:
决定 AI 能否真正进入生产系统、承担连续工作、创造可复用价值的,已经不只是模型本身,而是模型被放进了一个什么样的工作环境。
这正是 “Harness Engineering” 迅速升温的根本原因。
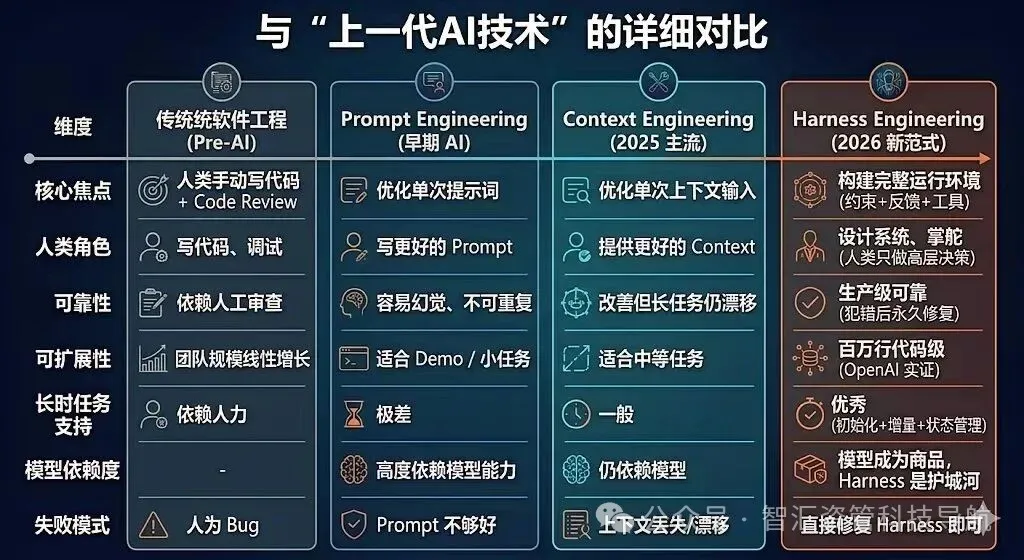
它不是一个简单的新名词,也不是 Prompt Engineering 换了个包装,更不是一次社交媒体上的概念炒作。它之所以被越来越多工程师、研究者和组织管理者认真对待,是因为大家开始同时撞上同一个问题:AI 会做事了,但还不会被稳定地使用。 而 Harness Engineering,讨论的正是这件事:如何把一个概率型、会偏航、会自我感觉良好、会复制错误模式的智能体,纳入一个可约束、可验证、可恢复、可审计的生产体系。 这也是 OpenAI、Anthropic 与一批前沿论文在 2026 年几乎同时把注意力投向 “harness” 的原因。(OpenAI[1])
一、Harness Engineering 真正解决的,不是“怎么把 AI 说服”,而是“怎么把 AI 管住”
如果要给这个概念一个更有解释力的定义,我会这样写:
Harness Engineering,本质上是在为 AI Agent 设计一整套运行制度:规定它能做什么、看到什么、如何行动、如何被验证、如何纠错、如何在长链路任务中持续保持连贯与边界感。
这个定义里最重要的词,不是 engineering,而是 制度。
因为今天很多团队对 AI 的误判,还停留在“模型够聪明,问题自然会消失”的阶段。 但真实情况恰恰相反:当 AI 从单轮问答进入多步执行、工具调用、代码修改、文档生成、任务交接和持续迭代之后,系统成败越来越取决于外部约束与反馈回路,而不是模型是否在某张 benchmark 上又高了几分。
OpenAI 在 2026 年 2 月公开复盘的 Codex 实验,给了这个判断一个极端但非常清晰的工业案例:他们从一个空仓库出发,连续五个月用 Codex 驱动一个真实产品的开发与交付,仓库规模达到约百万行代码,期间累计约 1500 个 PR,由一个极小工程团队推进。那篇文章最值得注意的,不只是“AI 写了多少代码”,而是作者反复强调:真正变化的,不是编码速度,而是工程师的工作重心——从写代码,转向设计脚手架、组织上下文、构建反馈循环、让 Agent 能可靠工作。(OpenAI[2])
这就是 Harness Engineering 的核心: 它研究的不是“怎么把一句 prompt 写得更漂亮”,而是“怎么给 AI 建一套工作制度,使它在复杂任务中不轻易失控”。
二、为什么这个概念会在 2026 年突然爆发?因为 Agent 已经从“会回答”进入“要负责”
很多流行概念的传播,靠的是包装;Harness Engineering 的传播,靠的是痛点。
过去在聊天、摘要、翻译、头脑风暴这些低风险任务里,AI 出错了,大多数时候只是“一次回答不够好”。 但当组织开始让 Agent 去写代码、改配置、调用 API、跑测试、读写文件、拆解计划、长时间持续执行时,失败模式就不再是“答错一点”,而是变成一整套新的系统问题:
- • 它会忘掉前文约束;
- • 会误判任务边界;
- • 会过早宣布完成;
- • 会把未验证的结果包装成已完成;
- • 会在长流程里逐渐漂移;
- • 会复制代码库中已有的坏模式;
- • 会在工具过多时变得更慢、更乱、更不可靠。
Anthropic 在长时程 Agent 的工程笔记里,把这个问题描述得很直白:Agent 其实很像一个不停换班、但每次上岗都“失忆”的工程师团队。为了解决这一点,他们专门把初始化 Agent 和执行 Agent 分层,让前者先建立环境、整理状态、写清功能列表与进度文件,再由后续执行 Agent 接力推进任务,并要求它先跑基本验证,再继续开发。(Anthropic[3])
这段经验很关键,因为它说明了一件事:\ 一旦任务是连续的、跨会话的、可执行的,AI 的问题就不再是“表达优化”,而是“运行治理”。
也正因此,Anthropic 在 2025 年底与 2026 年初的公开材料里已经频繁使用 “agent harness” 与 “evaluation harness” 这样的说法;OpenAI 则在 2026 年 2 月直接把 “Harness engineering” 公开命名为一个工程主题。与此同时,Mitchell Hashimoto 在 2026 年 2 月 5 日的文章中把 “Engineer the Harness” 提炼为一个清晰的方法论节点,进一步推动了这个术语的扩散。(Anthropic[4])
所以,Harness Engineering 之所以在这个时间点爆发,不是因为大家突然迷上了起名字,而是因为 Agent 真的开始进入工作现场了。\ 当 AI 不再只是展示能力,而要承担任务时,治理层就会被迫浮出水面。
三、它不是一个成熟学科,但已经是一种正在快速成形的研究对象
这里要非常严谨。
今天如果问:Harness Engineering 是不是一个边界稳定、定义统一、方法学成熟的学科? 答案仍然是否定的。
至少从 2026 年 3 月的公开文献来看,它还主要处于实践先行、学术命名与框架化正在跟进的阶段。最系统的一篇,是 2026 年 3 月 23 日发布在 Preprints.org 的《Harness Engineering for Language Agents: The Harness Layer as Control, Agency, and Runtime》。作者明确把 harness layer 提出来,尝试将其分解为 Control、Agency、Runtime 三个维度,并主张:很多 agent 能力并不是模型本体的孤立属性,而是 “模型—harness 系统” 的联合产物;同时他们还提出了 HarnessCard 这样的轻量披露格式,希望未来研究报告不只写模型,也写 harness。需要强调的是,这篇文章目前仍是未经过同行评审的预印本。(预印本网站[5])
几天后,3 月 26 日,arXiv 上又出现了《Natural-Language Agent Harnesses》。这篇论文提出了一个更前沿的问题:harness 能不能被外部化、可移植化、变成一个独立于特定运行时的可执行制品? 作者提出用自然语言来表达 harness 行为(NLAH),并用统一运行时 IHR 去执行这些 harness,以解决当前 agent 系统里 harness 深埋在控制器代码、默认配置、工具适配器和运行时假设中的问题。文章也明确标注为 under review。(arXiv[6])
同样在 2026 年 3 月,Meta-Harness 则把问题又往前推进了一层:如果 harness 很重要,那么 harness 本身能否被自动优化?这项工作提出让“提议者”作为一个能读代码、看历史、跑验证的 coding agent,在多个候选 harness 中基于失败轨迹做端到端搜索和改写,等于把“用 AI 管理 AI”的递归逻辑第一次以相对完整的方式摆上桌面。(arXiv[7])
这几篇工作的共同意义,不在于它们已经为 Harness Engineering 盖棺定论,而在于它们说明:\ 这个对象已经开始从工程经验,升级为被显式研究、被命名、被要求可披露和可复现的科学变量。
换句话说,Harness Engineering 今天还不是一个“成熟学科”,但它已经不是松散口号了。它正在成为一个研究对象、工程对象和组织对象。
四、真正值得重视的,不是概念本身,而是它背后的产业转向
如果只把 Harness Engineering 看成一个技术话题,仍然低估了它。
它之所以重要,还有一个更大的背景:模型能力正在快速逼近,但企业真正买单的竞争点,正在从“模型更强”转向“系统更稳”。
KPMG 在 2026 年 1 月发布的 AI Pulse 调研里给出了一个很有代表性的信号:连续两个季度,约 65% 的受访领导者都把 agentic system 的复杂性列为落地和扩展的首要障碍;与此同时,75% 的领导者把安全、合规与可审计性列为部署 AI agents 的关键要求。(KPMG[8])
这意味着什么?
意味着今天组织真正担心的,已经不只是“模型能不能干”,而是:
- • 它能不能在权限边界内干;
- • 干完能不能验证;
- • 出事能不能追溯;
- • 错了能不能回滚;
- • 长期运行会不会熵增失控;
- • 能不能纳入已有流程与责任体系。
这其实和云计算、数据库、容器编排、DevOps 的产业演化逻辑非常相似。 当底层能力越来越像平台能力,上层真正形成护城河的,往往是如何组织能力、如何约束能力、如何把能力嵌入生产体系。
所以,Harness Engineering 的战略意义,不在于它发明了一个全新的技术构件,而在于它提醒整个行业:\ AI 的竞争,正在从“谁更聪明”转向“谁更会治理智能”。
五、一个常被忽略的关键判断:Harness 不是为了让 AI 更自由,而是为了让 AI 更可信
很多人一谈 Agent,就天然把“更多工具、更强自主性、更少干预”视为进步。 但前沿实践给出的信号恰好更复杂:不是更自由就更强,往往是更有边界才更强。
这方面最值得拿出来讲的,不是理论,而是工程反例。
2025 年底,Vercel 公开复盘了一次非常典型的 agent 设计修正:他们最初给 text-to-SQL agent 配了很多工具,结果 agent 反而更困惑,步骤冗余、决策发散。后来他们反其道而行,砍掉约 80% 的工具,把系统极度简化为一个可执行 bash 的 file system agent。结果不是能力下降,而是成功率从 80% 升到 100%,步骤更少、token 更省、响应更快。(Vercel[9])
这件事很重要,因为它直接打破了一个直觉误区:\ Harness 不是往系统里不断加东西,而是给系统建立一套“足够用、可判断、可约束”的最小工作秩序。
Martin Fowler 体系中的观察也很值得参考。Thoughtworks 的 Birgitta Böckeler 在 2026 年 2 月解读 OpenAI 实践时,把其 harness 归纳为三类:上下文工程、架构约束与“垃圾回收”。她特别指出一个要害:如果你要的是可维护、可信赖的大规模 AI 生成系统,就必须接受某种程度上的“收窄解空间”——靠具体的架构模式、强制边界、标准化结构,来换取长期的信任与可靠性。(martinfowler.com[10])
这也是为什么 OpenAI 那篇文章里最发人深省的,不是它写了多少代码,而是它写下的这类经验: 当 Codex 出现问题时,修复方式几乎从来不是“让它再试一次”,而是反过来问:缺了什么能力、规则、工具或文档,应该怎样把它编码进系统,让 Agent 下次不再以同样方式犯错。(OpenAI[2])
所以,Harness 的本质从来不是“放大自主性”,而是把自主性变成一种可以托付的能力。
六、未来真正会留下来的,不是热词,而是三类基础设施能力
围绕 Harness Engineering,今天有两种常见误读。
一种是把它捧成“AI 时代一切问题的终极答案”; 另一种是把它贬成“老软件工程换皮”。
这两种说法都不准确。
更成熟的看法是:Harness Engineering 里有些部分会很快过时,有些部分会沉入基础设施层,真正留下来的,是三类结构性能力。
1. 可约束的执行边界
权限控制、审批机制、工具可见性、资源访问范围、动作白名单,这些都不是“当前模型不够强”的临时补丁。 只要 AI 还是概率系统,只要组织还需要责任边界,这类能力就不会消失。
2. 可验证的结果判定
只让 AI 自己说“完成了”,在低风险场景尚且勉强能用,在高价值链路中几乎等同于没有验收。 测试、lint、结构校验、状态比对、结果复核、独立检查代理,才是 agent 系统长期可用的基础。
Anthropic 在 evals note 中就明确指出,真正的 outcome 不是 agent 说了什么,而是环境最终留下了什么状态;evaluation harness 负责把任务、工具、记录、评分和聚合整个流程跑通。(Anthropic[11])
3. 可沉淀的组织记忆
Agent 的一个根本局限在于,它不会自然吸收制度。 所以每一次失败,如果不能沉淀为规则、文档、脚本、检查流程或环境改造,组织就只能不断重复交学费。
OpenAI 在 Codex 实验里后来干脆把“黄金原则”直接编码进仓库,并让后台任务定期扫描偏差、自动发起整理 PR,本质上就是把“人的审美和纪律”翻译成系统性的、可持续执行的秩序。(OpenAI[2])
这三件事合在一起,其实就是 Harness Engineering 未来真正的去向: 它未必会一直作为一个高热度名词存在,但它所承载的治理能力,会不断沉入 agent 平台、企业开发框架、审批流和运行时系统中,最后变成默认项,而不是选修项。
七、接下来最值得追踪的前沿,不是“提示词技巧”,而是三个更深的新议题
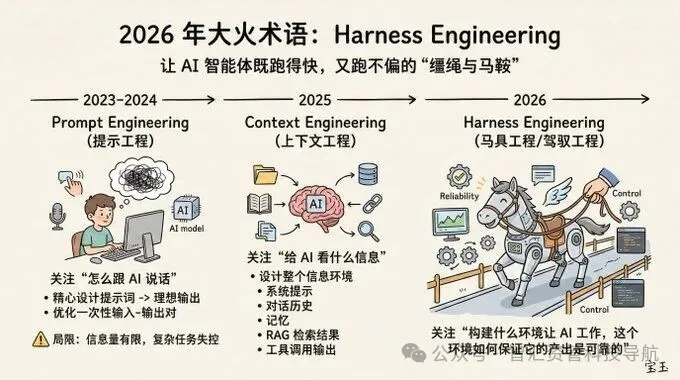
如果说 2024 年大家在谈 prompt,2025 年大家在谈 context,那么 2026 年更值得跟踪的,已经是下面这三个问题。
第一,Harness 的可移植性
今天很多 agent 系统号称“只差一个设计选择”,但实际上真正起作用的 harness 往往散落在控制器代码、运行时假设、工具中间层、文档约定和验证脚本里。 这导致两个系统很难公平对比,也很难做真正的消融实验。
NLAH 这类工作之所以值得看,不是因为它已经成为标准,而是因为它第一次比较完整地提出了一个问题:\ Harness 能不能像 Docker 镜像、CI 模板、infra module 一样,被表达、共享、迁移和复用? (arXiv[6])
如果这个方向继续推进,未来很可能会出现真正意义上的 “harness 市场”:不同任务类型、不同拓扑结构、不同合规级别,对应不同的可复用 harness 资产。
第二,Harness 的自动优化
Meta-Harness 把一个以前主要依靠资深工程师经验的动作,推向了自动搜索与自动改写。 这意味着将来最有价值的工作,可能不只是“手工做一个好 harness”,而是构建一个能持续从失败中学习、自己改进 harness 的系统。(arXiv[7])
这会带来一个非常深的产业后果: 未来企业真正需要的,可能不是“最强 agent”,而是“最会迭代 agent 工作制度的系统”。
第三,评估协议与 Harness 绑定披露
如果 harness 真能显著改变 agent 表现,那么只报模型、不报 harness,就会让很多实验结论变得不透明。 这正是那篇 2026 年 3 月预印本提出 HarnessCard 的原因:未来研究可能需要把运行时策略、状态持久化方式、上下文压缩、恢复机制、执行预算等,都视为影响结果的科学变量,而不是论文里的残余细节。(Sciety[12])
这件事听起来学术,实际上非常产业。 因为一旦行业开始把 harness 当成正式披露对象,组织的竞争优势就不再只体现在“模型选型”,而会更多体现在“系统设计能力”。
八、最重要的现实判断:不是所有任务都值得上 Harness,真正的高手是会做“治理分层”
说到底,Harness Engineering 最大的风险,不是没人做,而是所有场景都想做重治理。
这会很快把团队拖进另一个极端:流程越来越厚,配置越来越复杂,维护成本越来越高,最后治理成本吞掉了原本的效率收益。
所以,真正成熟的判断,不是“要不要拥抱 Harness”,而是:
什么任务值得上到哪一层 Harness?
我的判断标准很简单。以下任务更值得重投入:
- • 长链路、多步骤;
- • 有工具调用、环境读写或外部系统操作;
- • 出错代价高;
- • 可建立明确验收标准;
- • 任务会被重复执行;
- • 需要跨人或跨 Agent 协作;
- • 需要审计、回滚、审批或责任界定。
像代码生成、持续运维、研究流程、企业工作流自动化、结构化文档处理,这些场景往往值得认真做 harness。 反过来,一次性问答、灵感型写作、低风险草稿、纯开放表达,很多时候根本不配复杂治理。
OpenAI 自己也在文章里提醒了一个常被忽视的事实:他们的很多效果依赖于仓库结构、文档组织、工具能力与长期投入,不能被想当然地外推为“所有团队都立刻可复制”。(OpenAI[2])
所以,Harness Engineering 的正确姿势,不是普遍化,而是分层化。 不是“把一切都制度化”,而是“把高价值、高风险、高频复用的部分优先制度化”。
九、真正的大趋势:软件工程的重心,正在从“写代码”迁移到“设计智能工作的环境”
如果把所有这些现象放在一起看,会发现我们其实正在经历一个非常大的范式转移。
OpenAI 用 Codex 的实验展示了一个极端样本:仓库可以从零开始由 agent 生成,工程师的主要职责变成设计环境和反馈回路。(OpenAI[2]) Anthropic 的实践则说明,长时程 agent 的表现高度依赖初始化、状态管理和验证顺序。(Anthropic[3]) Mitchell Hashimoto 把这一转变总结为 “Engineer the Harness”;Karpathy 则在 2026 年初公开提出 “agentic engineering”,把人类角色描述为对 agent 的指挥、监督与编排,而不是继续手工完成大部分代码生产。(Mitchell Hashimoto[13])
这几条线索放在一起,指向的是同一个结论:
未来最稀缺的,不是“会不会调用模型”,而是“会不会设计一个让模型长期可靠工作的环境”。
这不是一个小修小补的技能变化,而是一种工程对象的迁移。 过去,工程师主要直接操作代码; 现在,越来越多时候,工程师操作的是:
- • 规范与约束;
- • 知识组织;
- • 验证机制;
- • 审批与回滚;
- • 多 Agent 协同流程;
- • 持续纠错与沉淀系统。
换句话说,软件工程的重心,正在从“构建软件本身”,部分迁移为“构建让智能可靠生产软件的制度环境”。
这才是 Harness Engineering 最深的一层含义。
结语:Harness Engineering 真正改变的,不是工具,而是组织对 AI 的管理方式
如果把整篇文章压缩成一句判断,我会这样写:
Harness Engineering 的本质,不是又发明了一种新技术,而是把 AI 使用的重点,从“怎么把它说清楚”,推进到“怎么把它纳入一个可治理、可验证、可追责、可持续优化的生产系统”。
它不是伪概念,因为它回应的是现实中最棘手的 Agent 落地问题; 它也不是铁律,因为它并不会在所有场景里都带来正收益; 它更像一个正在快速成形的行业范式:在复杂、多步、可执行、可验证的任务里,它会越来越接近决定成败的基础设施;在简单、一次性、低风险任务里,它又完全不值得被神化。(预印本网站[5])
未来会被淘汰的,是那些为了弥补模型暂时短板而堆出来的脆弱小技巧; 真正会留下来的,是围绕约束、验证、权限、审计、回滚、沉淀构建起来的治理能力。
因为当 AI 真正进入工作现场,问题就不再只是:
“它会不会做。”
而是:
“它能不能在制度中,被持续、稳定、低风险地使用。”
这,才是 Harness Engineering 真正值得被认真讨论的原因。
引用链接
[1] Harness engineering: leveraging Codex in an agent-first ...:https://openai.com/index/harness-engineering/?utm_source=chatgpt.com
[2]Harness engineering: leveraging Codex in an agent-first world | OpenAI:https://openai.com/index/harness-engineering/
[3]Effective harnesses for long-running agents \ Anthropic:https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents
[4]Effective harnesses for long-running agents:https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents?utm_source=chatgpt.com
[5]Harness Engineering for Language Agents: The Harness Layer as Control, Agency, and Runtime[v1] | Preprints.org:https://www.preprints.org/manuscript/202603.1756
[6][2603.25723] Natural-Language Agent Harnesses:https://arxiv.org/abs/2603.25723
[7]Meta-Harness: End-to-End Optimization of Model Harnesses:https://arxiv.org/html/2603.28052v1
[8]AI at Scale: How 2025 Set the Stage for Agent-Driven Enterprise Reinvention in 2026:https://kpmg.com/us/en/media/news/q4-ai-pulse.html
[9]We removed 80% of our agent’s tools - Vercel:https://vercel.com/blog/we-removed-80-percent-of-our-agents-tools
[10]Harness Engineering:https://martinfowler.com/articles/exploring-gen-ai/harness-engineering.html
[11]Demystifying evals for AI agents:https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents?utm_source=chatgpt.com
[12]The Harness Layer as Control, Agency, and Runtime - Sciety:https://sciety.org/articles/activity/10.20944/preprints202603.1756.v1?utm_source=chatgpt.com
[13]My AI Adoption Journey – Mitchell Hashimoto: https://mitchellh.com/writing/my-ai-adoption-journey